
A couple of months ago, I wrote a column on Search Engine Land titled Why Big Testing Will Be Bigger Than Big Data. A shorter spin-off of my post here on the big data bubble in marketing, its overarching message was that in a world of ever more data, experimentation would inevitably become king.
The message seemed to resonate, and the article was widely shared. However, my suggestion that the number of people empowered to run experiments should be significantly expanded in most organizations raised a number of questions in the comments. How do you build and scale a testing culture in a company?

The column and those questions caught the attention of Andy Pulkstenis, whom I would describe as a Jedi Knight of experimental design. He’s had years of experience running marketing-oriented controlled experiments at Capital One — one of the world’s pioneers in large-scale marketing experimentation programs — and now at State Farm.
Andy’s an enthusiastic champion of developing a “testing culture,” and he gave a popular presentation on the subject at SAS’s Analytics 2012 conference last year. He and I had the opportunity to chat, and he agreed to participate in the following Q&A on testing on the big stage. All the graphics in this post were created by him.
Can you start by telling us a little bit about your background and your role at State Farm?
I have an MS in Statistics from Penn State, and have been working in applied business analytics and predictive modeling for about 18 years now. I spent 8 years working for a firm that did statistical consulting and a lot of SAS, then spent 6 years at Capital One leading statistical analytic teams in a variety of departments. I’ve been at State Farm doing the same thing for the past 4 years.
I dabbled in testing off and on before Capital One, but it was there that I feel I really learned how to do testing. I was fortunate to work directly with a few mentors who had significant experience in testing and DOE and really knew the math behind the machinery as well. Bill Kahn and Tom Kirchoff were instrumental in my development as an experimenter.
What are your arguments for why marketers should engage in testing, specifically controlled experiments?
There are several. But the most basic is that if you are not testing, you never really know what’s driving customer behavior.
If you are not testing, you never really know what’s driving customer behavior.
In response to a business partner proclaiming what they believed to be truth about customer behavior, one of my colleagues said, “Do you know, or do you just think you know?” I’ve stolen that mantra and use it often in my own business discussions. When push comes to shove, observational data (data that did not come from randomized, controlled experiments) generates theories about what may be happening, but to really know causation with certainty requires a controlled experiment.
I sat in a talk a while back where the lecturer discussed observational studies — you know the ones, where they announce on TV that coffee or wine or whatever is bad for you, then the newspaper the next day says a study showed it’s good for you, then next month the same newspaper runs a contradictory story. He said that a group took dozens of observational studies, replicated each one in a controlled experimental environment, and in a whopping 80% of cases failed to reach the same conclusion as the uncontrolled observational study.
80%!
That should send chills down the spine of any business or marketing analyst when you consider that the vast majority of what passes for business analysis today is essentially an uncontrolled, observational data study, since 95% of the data in any large company is uncontrolled observational data. Clean data from an experiment gives clean answers, and if the sample is chosen properly the data can be used as the foundation for spectacular predictive models going forward.
The vast majority of what passes for business analysis today is essentially an uncontrolled, observational data study.
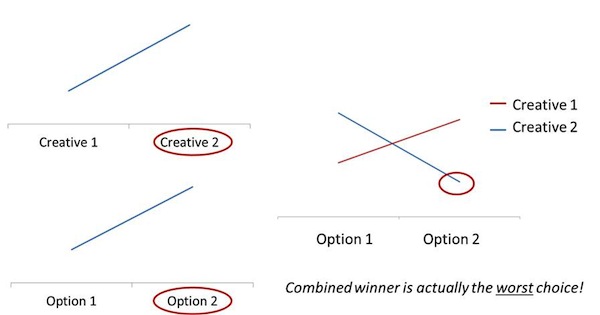
A related question that comes up often is “Why multivariate testing instead of A/B testing?” I think both have their place, but a firm that stops with simple A/B testing is really limiting potential for growth. In an A/B testing direct mail setting, for example, you learn which letter generated higher response, but you don’t learn why it worked because there were too many simultaneous differences between the letters.
Some practitioners try to mitigate that by OFAT (One Factor At a Time) testing — changing only one feature between the letters in the first A/B test, pick the winner, then change only a second feature in a second A/B test, combine that with the learnings from the first, etc., but this also has significant drawbacks (the most obvious is longer time to a decision).
A more detrimental drawback is that to combine conclusions across tests from different time periods makes some pretty bold assumptions about the lack of interactions, the lack of seasonality, and the lack of impact from exogenous factors like the economy or competitive environment. We demonstrated this for partners at State Farm using our internal data, from a real experiment, showing that the combined solution was actually the worst choice of overall strategy. (See graphic below.)
How can a marketer champion testing in their organization?
You need to be a teacher and be willing to proactively sell this idea to anyone and everyone that will listen. I did that for about 2 months (and many audiences) before finding a willing business partner to try this “new” idea. They all liked the idea, but it took a while to find someone willing to go first.
Initially it’s about educating on the advantages of testing compared to observational analysis, sharing examples on how other firms are using it to improve business strategies, and I found value in answering some common arguments I’ve encountered right there in the first presentation, such as “it’s too expensive” or “it seems too complicated compared to what we do today.” I go down the list of about a dozen of them, and answer each one by one. This addresses 95% of the concerns in most groups before you even get to Q&A.
Initially it’s about educating on the advantages of testing compared to observational analysis.
How do you win executive-level buy-in?
Conceptual buy-in is easy, but commitment to let you do this with a real business strategy can be another thing entirely.
Getting the right initial internal example is really important. If it’s too small, people don’t notice and it doesn’t really feel compelling. If it’s too big and errors occur, it becomes a high profile example people can latch onto for why we may not want to do testing. So aiming for an example of moderate impact but smaller and very manageable scope has worked for me. That opens doors to larger opportunities once the internal proof of concept is out there.
Telling people how other companies are improving business results through testing is helpful, but it’s very powerful when you can switch to telling people how other business units in your own firm have used testing to improve business results. Our first “big” multivariate test was 24 strategies, which felt ambitious at the time. Our follow-up in that same business area was over 200.
From your experience, what are the ingredients that make for a successful testing project?
1) The right SME’s representing the following 4 areas: The business, statistical design, implementation, and creative design (the guys making the marketing piece or web page, for example). Leaving any one of those 4 out causes many problems. Drop implementation, and the other guys create a great test that will crash our system. Drop the stats guy and the others can create a great test that doesn’t actually answer the questions accurately. Drop the business guy and the others create a great test that answers questions no one is asking, etc.
Drop the business guy and the others create a great test that answers questions no one is asking.
2) Monitoring, monitoring, monitoring! The work doesn’t end when it goes to implementation. There must be close monitoring of the test from start to finish, because you’d be surprised how many times someone makes a decision to “help out” that can destroy the statistical integrity of the test.
We had one web test where we needed to battle someone in implementation who believed that if someone visits the page, leaves, and comes back, we should continue to randomize which page he sees (versus fixing it to be the originally randomized page for all return visits for that guy). This, of course, completely destroys the ability to interpret the test factors because now they are all jumbled together. Was the response due to page 1? Page 2? The 3rd page he saw? A combination of all 3? We caught this in post-implementation monitoring and were able to correct it early on, only losing a couple of days.
3) Have a clear analysis plan before the test is even designed, including approach and metrics of interest. The analysis plan and statistical design are linked, and ignoring the analysis plan can lead to a design that doesn’t allow you to carry out the analysis as intended.
For example, you may intend to study interactions, but the design may assume no interactions exist. You usually can’t fix something like that on the back end. Maybe you plan to analyze the data at the customer-level, but the implementation platform produces only aggregate data. Best to get this stuff straightened out in the beginning so there are no surprises on the back end.
As you scale up testing in an organization, how can you manage the process to avoid conflicts, such as one test interfering with another?
We’re currently tackling this challenge. It can be helpful to start first with a siloed prioritization approach, within each channel or business line, for example. When the same stakeholders are the ones causing the problems, it’s easier to resolve. We’ve got that handled pretty well in our firm.
The next step is creating a firmwide prioritization process, for those instances where two competing business units want to use the same space at the same time. Some decisions will be easy as usually there is a widespread awareness of which business units trump others or which strategies are more “important” than others.
Failing that, you need to get the associated stakeholders in a room and hammer it out with the company’s best interests at the heart of the conversation. The dimensions I consider include financial impact, strategic impact, complexity (can we squeeze a less important test in first because it’s simple and not really lose much overall as a company?), and the impacts of delaying an effort until later.
If you could offer 30 seconds of advice to CMOs about controlled experimentation in marketing, what would you say?
If you aren’t testing, you are guessing. The guesses may be based on years of good experience and some halfway decent data, but they are still guesses and educated hunches more than verified truth.
If you aren’t testing, you are guessing. The guesses may be based on years of good experience and some halfway decent data, but they are still guesses.
If you want to know, with certainty, you must test. And it’s the new normal. The ones that refuse to embrace testing will find themselves at a severe disadvantage as more and more competitors in all industries start to test. And learn about interactions — they will likely change the way you think about your strategies.
Thank you, Andy — this was awesome!


You should have read the article printed many years ago concerning the use of science to develop advertising/marketing strategy. We used Taguchi methods at a local auto dealership, and with focus groups and participation of key dealership personel, we tested multiple advertising themes in our local community to see what drew them in and then ended up purchasing a new car. It was an incredible achievement as the best idea set the stage for doubling the sales. The real benefit was lower advertising costs, greater actual sales success was achieved. Dick and Michele Morrissett with great input from Ranjit Roy